Basics of Seccomp for Docker
Seccomp is a kernel feature that allows you to filter syscalls for a specified process. In this article, you'll learn how to use strict and eBPF modes with your existing Docker configuration.


Hello World! Welcome to yet another docker security post. In of my older posts, which is "Breakout from the Seccomp Unconfined Container", you have seen how to run a docker with an unconfined seccomp security option and exploit the CAP_SYS_MODULE capability on the container to break out of it. Well, in this post, I will be discussing what seccomp is and how you can configure it with your existing Docker environment.
What is Seccomp?
Seccomp is a syscall implemented in the Linux kernel since the v3.17 version release, and as the man page says –
operate on Secure Computing state of the process
The system calls are implemented during development and then called during the execution of the process. There are two main operations we will be discussing here: SECCOMP_SET_MODE_STRICT and SECCOMP_SET_MODE_FILTER.

The above image is basically depicts how the information is transferred from user-space to kernel-space. I got this while reading the research paper "A Trustworthy In-Kernel Interpreter Infrastructure".
Difference between MAC and Seccomp
It is different from the Mandatory Access Controls, like AppArmor, which let you write a profile for the program binaries in plain text with certain syntax and load them in the kernel. This will be then applied to all the processes created by that binary, and deny all the entries which are explicitly marked to do so, whether or not in the profile list. But, in the case of seccomp, the developers have full control over when, how, and what all syscalls are supposed to be filtered.
You can disable the MAC services either by stopping the services, removing the kernel modules or even uninstalling the package. But since, seccomp is implemented in the kernel itself, it can not be removed after 3.17 kernel version. This makes it more powerful than any other security solution.
In case you are wondering what "Mandatory Access Control" is, it is another way to run confined docker containers, usually done with the help of AppArmor. I have written a mini-series on it for you. You can find it here: AppArmor Basics for Sysadmins
Write your First Seccomp Application
I have created a simple program for demonstrating the working of the SECCOMP_SET_MODE_STRICT mode. This one is very easy to understand as it allows only a set of syscalls and block all the remaining.
- read
- write
- _exit (implemented by exit())
- exit_group
- sigreturn
Other system calls result in the termination of the calling thread, or termination of the entire process with the SIGKILL signal when there is only one thread.
#include <fcntl.h>
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#include <linux/seccomp.h>
#include <sys/prctl.h>
int main(int argc, char ** argv) {
if (argc < 3) {
fprintf(stderr, "usage: %s <file> <text>\n\n", argv[0]);
return 0x1;
}
// this works
int output = open(argv[1], O_WRONLY | O_CREAT);
printf("Setting seccomp in strict mode:\n");
prctl(PR_SET_SECCOMP, SECCOMP_MODE_STRICT); // from the seccomp man page
// only this line will work
write(output, argv[2], strlen(argv[2]) + 1);
printf("write() syscall completed!\n");
// program will be now killed
int output2 = open(argv[1], O_WRONLY | O_CREAT);
printf("openat() syscall succeed\n");
return 0x0;
}SECCOMP_SET_MODE_STRICTLet's compile it using gcc and run it. You will find out that the open syscall succeeds at first, but later it failed because this time the kernel knows what to filter and how to handle it if program tries to execute it.
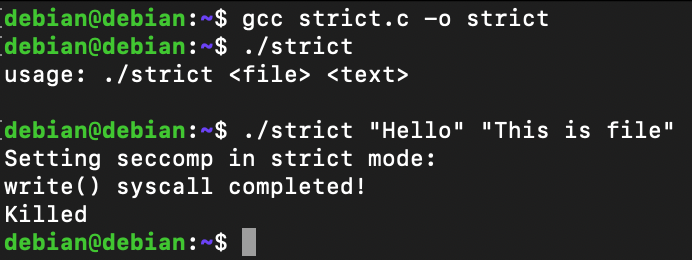
Don't trust me blindly; I have an output of strace ready for you. In this case, after openat and write syscalls, there is a call to prctl which is setting the seccomp in strict mode. Therefore, when another call to openat was initiated, but before it could return any value, it is supposed to be killed with a SIGKILL signal.
openat(AT_FDCWD, "Hello", O_WRONLY|O_CREAT, 057610) = 3
write(1, "Setting seccomp in strict mode:\n", 32Setting seccomp in strict mode:
) = 32
prctl(PR_SET_SECCOMP, SECCOMP_MODE_STRICT) = 0
write(3, "This is file\0", 13) = 13
write(1, "write() syscall completed!\n", 27write() syscall completed!
) = 27
openat(AT_FDCWD, "Hello", O_WRONLY|O_CREAT, 025204) = ?
+++ killed by SIGKILL +++
KilledNote: The prctl is another syscall used to manipulate certain behaviours of the running process or thread. Advanced eBPF Filtering with Granular Control
The strict mode is pretty cool and secure, we have seen that. But in the real case, there are a lot of syscalls involved and the strict mode doesn't meet the requirements. Therefore, the advanced filtering using the eBPF filter comes into play. It is implemented by another mode in the seccomp, known as SECCOMP_SET_MODE_FILTER.
With this developers or the users (if implemented by developer) could have full control on allowing or disallowing the syscalls at runtime, without hard-coding in the the program itself.
Unfortunately, its demonstration on the man page looks so scary, if you are a newbie or inexperienced in the C programming language, (I am at least 🥲), To make things a lot easier for this post and you, I have found an answer on StackExchange which uses certain helper functions for this.

Let's copy the source code from this answer for now, and modify it to disallow the read function, and return EBADF error, which is also known as "Error Bad File".
#include <seccomp.h>
#include <unistd.h>
#include <stdio.h>
#include <errno.h>
#include <string.h>
#include <fcntl.h>
#include <stdlib.h>
int main(int argc, char **argv)
{
if (argc < 2) {
fprintf(stderr, "usage: %s <file>\n", argv[0]);
return 0x1;
}
/* initialize the libseccomp context */
scmp_filter_ctx ctx = seccomp_init(SCMP_ACT_KILL);
/* allow exiting */
seccomp_rule_add(ctx, SCMP_ACT_ALLOW, SCMP_SYS(exit_group), 0);
/* allow getting the current pid */
seccomp_rule_add(ctx, SCMP_ACT_ALLOW, SCMP_SYS(getpid), 0);
/* allow changing data segment size, as required by glibc */
seccomp_rule_add(ctx, SCMP_ACT_ALLOW, SCMP_SYS(brk), 0);
/* allow writing up to 512 bytes to fd 1 */
seccomp_rule_add(ctx, SCMP_ACT_ALLOW, SCMP_SYS(write), 2,
SCMP_A0(SCMP_CMP_EQ, 1),
SCMP_A2(SCMP_CMP_LE, 512));
/* open file and read first 5 chars */
int file = open(argv[1], O_RDONLY);
char *buff = (char*)malloc(6);
memset(buff, 0x0, 0x6);
read(file, (void*)buff, 0x5);
printf("Buffer read #1: %s\n", buff);
memset(buff, 0x0, 0x6);
read(file, (void*)buff, 0x5);
printf("Buffer read #2: %s\n", buff);
/* if writing to any other fd, return -EBADF */
seccomp_rule_add(ctx, SCMP_ACT_ERRNO(EBADF), SCMP_SYS(read), 0);
/* load and enforce the filters */
seccomp_load(ctx);
seccomp_release(ctx);
printf("this process is %d\n", getpid());
/* read the 5 bytes again after seccomp read deny */
memset(buff, 0x0, 0x6);
read(file, (void*)buff, 0x5);
printf("Buffer read #3: %s\n", buff);
free(buff);
buff = NULL;
return 0x0;
}EBADF error.Since these functions are defined in the libseccomp.so library, therefore, at link time use -lseccomp to include the references of the required functions in the binary.
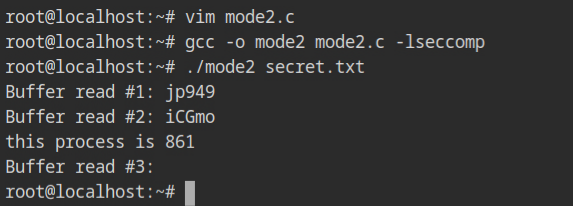
What is wrong with the output? Why is it not getting killed, like in strict mode? Because the killing process was the default in the strict mode. In this case, the read syscall's filter is allowed to return with an EBADF error instead of killing, so the programme continued and returned the error in the third call.
read(3, "jp949", 5) = 5
Buffer read #1: jp949
read(3, "iCGmo", 5) = 5
Buffer read #2: iCGmo
seccomp(SECCOMP_SET_MODE_FILTER, 0, {len=22, filter=0x5641b027e350}) = 0
this process is 770141
read(3, 0x5641b027c5d0, 5) = -1 EBADF (Bad file descriptor)
Buffer read #3:
+++ exited with 0 +++
Even though the file description number is correct in the first argument, the return value is -1 (EBADF), as defined in the seccomp filter.
Seccomp Profile of Docker
Docker uses eBPF mode instead which gives the power to the developers to decide which syscall should be allowed or blocked for individual containers. By default, it would use the configuration from the moby project, https://github.com/moby/moby/blob/master/profiles/seccomp/default.json for all the containers.
You can either disable it using --security-opt seccomp=unconfined or profile your own JSON config using --security-opt seccomp=/path/to/profile.json while creating or running the container using docker CLI.
Let's have the following profile to disallow mkdir, socket and connect syscalls, which would return Operation not Permitted error while executing mkdir and ping command.
{
"defaultAction": "SCMP_ACT_ALLOW",
"syscalls": [
{
"name": "mkdir",
"action": "SCMP_ACT_ERRNO"
},
{
"names": [
"socket",
"connect"
],
"action": "SCMP_ACT_ERRNO"
}
]
}Run the container with the appropriate security option command, --security-opt seccomp=myprofile.json and try to execute the ping or mkdir command, even if you are a root user in the container.
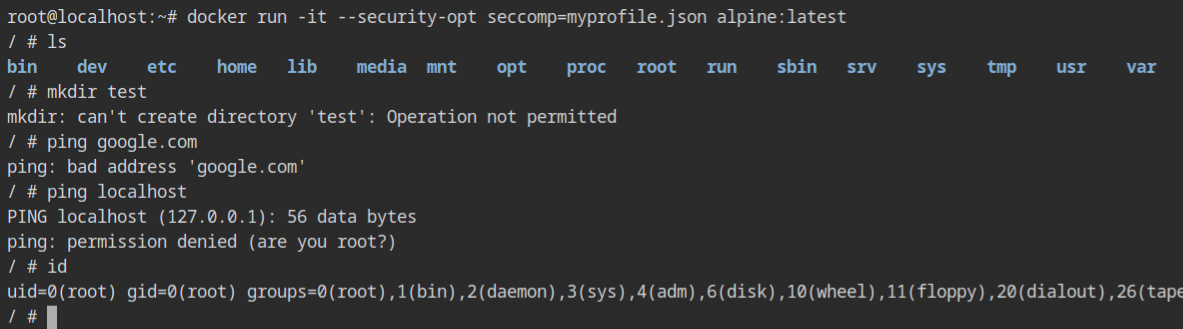
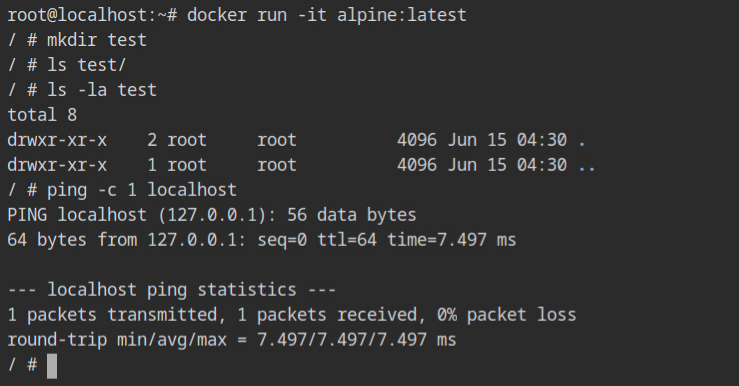
myprofile.json security optionWith the default profile, all the above commands work as expected. This confirms that seccomp is effective in the container even if you are running as the root user. Therefore, it is a trustworthy solution for setting up a secure containerized environment on your production infrastructure.
Resources
- https://docs.docker.com/engine/security/seccomp/
- https://www.researchgate.net/publication/302574274_Jitk_A_Trustworthy_In-Kernel_Interpreter_Infrastructure
- https://security.stackexchange.com/questions/168452/how-is-sandboxing-implemented/175373
- https://github.com/moby/moby/blob/master/profiles/seccomp/default.json
- https://tbhaxor.com/apparmor-basics-for-sysadmins