How does Docker run Containers Under the Hood
In this post, I'll show you how docker works behind the scenes and how to spawn containers using containerd and runc as the main runtime. What's more, how does it start the program from ENTRYPOINT.


Hello, world! So far you have been learning about the docker and how to exploit the misconfiguration in the containerized environment. Recently, I watched the @LiveOverflow video on containers and namespaces, and it inspired to me dig deeper to learn how actually containers work under the hood. Have some caffeine available since this post is going to be a bit longer. 😀.
The following experiment is done with the 20.10.16 version of the docker on Arch Linux, output may vary on the different operating systems or docker versions, but the concept will be almost the same.
If you are on this blog for the first time, I would recommend you first read Understanding the Container Architecture, this is an advanced article.
On the high level, when the container is started, runc and containerd change the root filesystem to the new folder containing all the required files and implement all the namespace creation using unshare command, which uses unshare syscall under the hood, and then finally the pivot_root is used to change the root and then the entry point defined in the image is executed.
containerd - The Middle Man
From the website of containerd – https://containerd.io/
It manages the complete container lifecycle of its host system, from image transfer and storage to container execution and supervision to low-level storage to network attachments and beyond.
When the dockerd receives information, formats it and then sends it to the containerd, which then set up the directory for runc with the files like config.json and options.json,
chdir("/var/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/9cec00b45bcf2c7424440102155bca808737bf6594895be22f104fcb1c4096f7") = 0containerd process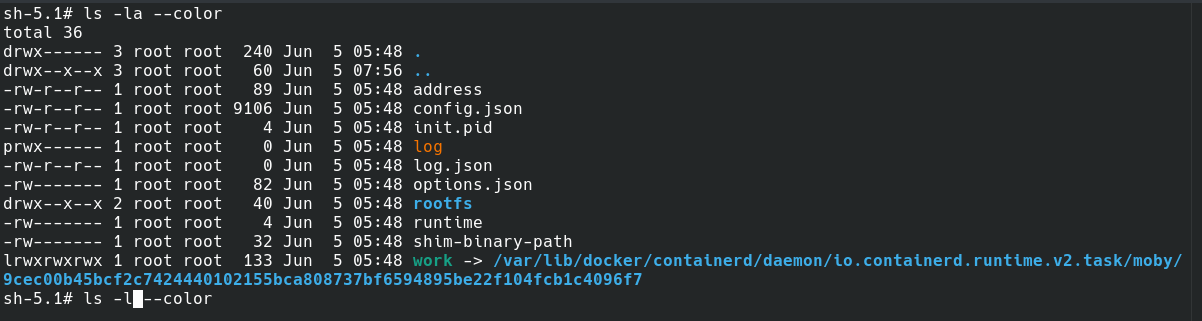
You will realize that this rootfs directory is empty. Actually, it is provided in the config.json file in the root key. I haven't configured rootless mode with docker yet, so the engine is configured to use the overlay2 filesystem.
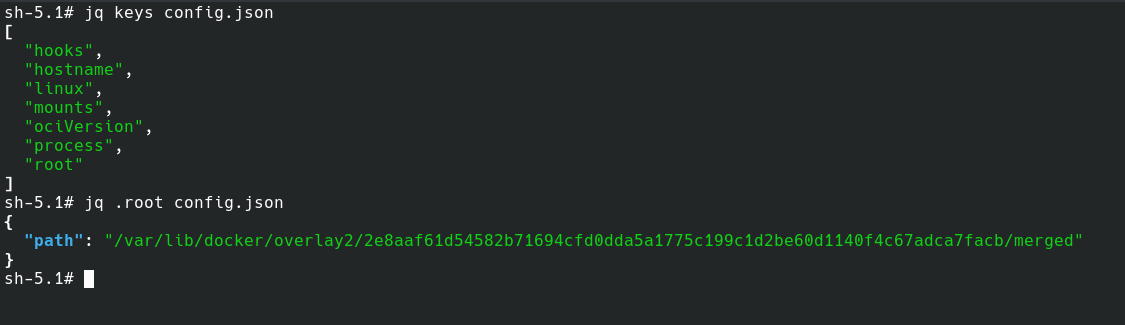
config.json fileThe meaning of "merged" here is that all the layers in the fsLayers property of the image manifest files are now clubbed into one directory, aka rootfs. So this directory will contain all the children of the root (/) path in the container.
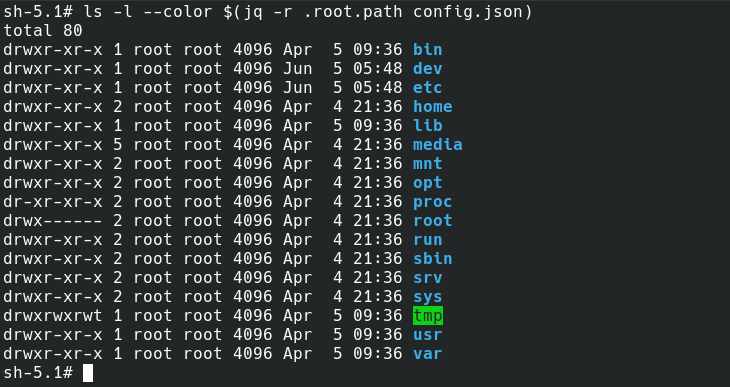
.root.path directory in config.jsonOur containerd is so busy, that it will not only wait for one container. Therefore it will start a shim (you can also call it a slave) process and be ready for the next container operations. This newly created shim process is now responsible to run and monitor the container and report the containerd (master) in case it is stopped anyhow, to do the cleanup. In this case, the shim process name is containerd-shim-runc-v2.
execve("/usr/bin/containerd-shim-runc-v2", ["/usr/bin/containerd-shim-runc-v2", "-namespace", "moby", "-address", "/var/run/docker/containerd/containerd.sock", "-publish-binary", "/usr/bin/containerd", "-id", "9cec00b45bcf2c7424440102155bca808737bf6594895be22f104fcb1c4096f7", "start"]) <unfinished ...> containerd-shim process
ps command outputrunc – The hardworking dude
When it comes to actually running the container, it is used for such work load and yet not rewarded with enough discussion, poor dude 😅.
From the GitHub of runc – https://github.com/opencontainers/runc
It is a tool for spawning and running containers on Linux according to the Open Container Initiative specification. Therefore, it is responsible for interpreting the config.json file.The very first step is to setup a cgroup container for each container, distinguished by their hex id.
openat(AT_FDCWD, "/sys/fs/cgroup/system.slice/docker-9cec00b45bcf2c7424440102155bca808737bf6594895be22f104fcb1c4096f7.scope", O_RDONLY|O_DIRECTORY) = 15cgroup for the containerIt then creates the namespaces for mount, UTS, System V IPC, PID and network namespace first. After then it create the cgroup namespace so that it could virtualize the cgroup containers for security and confinement. It also eases tasks such as container migration.
unshare(CLONE_NEWNS|CLONE_NEWUTS|CLONE_NEWIPC|CLONE_NEWPID|CLONE_NEWNET) = 0 ... snip ... unshare(CLONE_NEWCGROUP) = 0 Now comes the main part, where runc will go to the "rootfs" directory of the container, perform pivot_root and then start the program after loading the which is usually defined in the ENTRYPOINT entrypoint.
chdir("/var/lib/docker/overlay2/2e8aaf61d54582b71694cfd0dda5a1775c199c1d2be60d1140f4c67adca7facb/merged") = 0
openat(AT_FDCWD, "/", O_RDONLY|O_DIRECTORY) = 8
openat(AT_FDCWD, "/var/lib/docker/overlay2/2e8aaf61d54582b71694cfd0dda5a1775c199c1d2be60d1140f4c67adca7facb/merged", O_RDONLY|O_DIRECTORY) = 12
pivot_root(".", ".") = 0
chdir("/") = 0
... snip ...
execve("/usr/local/bin/docker-entrypoint.sh", ["docker-entrypoint.sh", "bash"]) <unfinished ...>
... snip ...
openat(AT_FDCWD, "/sys/fs/cgroup/cgroup.controllers", O_RDONLY|O_CLOEXEC) = 21
openat(AT_FDCWD, "/sys/fs/cgroup/cgroup.subtree_control", O_WRONLY|O_CLOEXEC) = 21
openat(AT_FDCWD, "/sys/fs/cgroup/system.slice/cgroup.subtree_control", O_WRONLY|O_CLOEXEC) = 21
execve("/usr/local/bin/bash", ["bash"], 0x7febfae41020 /* 10 vars */) = 0
Now if you will stop the container, containerd-shim process will report this to the containerd and will use runc to delete the running container.
chdir("/var/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/9cec00b45bcf2c7424440102155bca808737bf6594895be22f104fcb1c4096f7") = 0
execve("/usr/bin/containerd-shim-runc-v2", ["/usr/bin/containerd-shim-runc-v2", "-namespace", "moby", "-address", "/var/run/docker/containerd/containerd.sock", "-publish-binary", "/usr/bin/containerd", "-id", "9cec00b45bcf2c7424440102155bca808737bf6594895be22f104fcb1c4096f7", "-bundle", "/var/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/9cec00b45bcf2c7424440102155bca808737bf6594895be22f104fcb1c4096f7", "delete"], 0xc0007e0900 /* 17 vars */ <unfinished ...>
... snip ...
execve("/usr/bin/runc", ["runc", "--root", "/var/run/docker/runtime-runc/moby", "--log", "/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/9cec00b45bcf2c7424440102155bca808737bf6594895be22f104fcb1c4096f7/log.json", "--log-format", "json", "delete", "--force", "9cec00b45bcf2c7424440102155bca808737bf6594895be22f104fcb1c4096f7"], 0xc000182240 /* 17 vars */ <unfinished ...>
... snip ...
unlinkat(AT_FDCWD, "/var/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/9cec00b45bcf2c7424440102155bca808737bf6594895be22f104fcb1c4096f7/rootfs", 0) = -1 EISDIR (Is a directory)
unlinkat(AT_FDCWD, "/var/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/9cec00b45bcf2c7424440102155bca808737bf6594895be22f104fcb1c4096f7/rootfs", AT_REMOVEDIR) = 0
unlinkat(AT_FDCWD, "/var/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/.9cec00b45bcf2c7424440102155bca808737bf6594895be22f104fcb1c4096f7", 0) = -1 EISDIR (Is a directory)
unlinkat(AT_FDCWD, "/var/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/.9cec00b45bcf2c7424440102155bca808737bf6594895be22f104fcb1c4096f7", AT_REMOVEDIR) = -1 ENOTEMPTY (Directory not empty)Conclusion
So we have understood that containers are nothing but a confined namespaces whose root is changed by pivot_root. Since the syscall involved in the setting containers by runc are available in Linux, in case of Windows or MacOS a Linux VM is installed while setting up docker desktop.
The processes in the containers run on machine host and with the username same as of root user or the current user (rootless mode), therefore it is not a actually virtualization, it is a process level isolation because of PID namespace mainly.
Resources
- https://www.youtube.com/watch?v=-YnMr1lj4Z8&list=PLhixgUqwRTjxtDt2ABuejRxrIFSroqyEY&index=4
- https://man7.org/linux/man-pages/man7/cgroup_namespaces.7.html#NOTES
- https://www.threatstack.com/blog/deep-dive-runtimes-kubernetes-cri-and-shims
- https://nanikgolang.netlify.app/post/containers/
- https://iximiuz.com/en/posts/implementing-container-runtime-shim/