Why Pivot Root is Used for Containers
In this post, you will learn about the differences between only chroot and chroot after pivot_root in detail. You will realise the reason why it is used in containerization.


Hello world! In one of my earlier articles on Linux security, I mentioned the issues with the chroot implementation and how they can be exploited using a very straightforward "double chroot technique." The docker team has decided to abandon chroot and switch to pivot root because, occasionally, root privileges (or CAP_SYS_CHROOT is allowed), are required while debugging in the container, making chroot an unsuitable option.
What is the Pivot Root anyway?
It is necessary to provide security when running containers in different namespaces so that two processes running in separate namespaces don't conflict with one another. Because the chroot is applied to the active process and its children but doesn't alter the root and mount table in global namespace, it becomes easy to breakout of the jail and access the filesystem from host. I explained this in my earlier posts on chroot breakout, I would recommend you to check out the following link.

Your OS state may become unstable if you change the root directory in the outside namespace because it will mess up the root directory for other processes. Although I haven't tested it out and am not completely certain, I have a feeling that it will be the case.
You are aware that runc also creates new mount namespaces, after which it performs a pivot root in the new namespace to update the mount's root directory. To be more precise, it changes the mount's root inside namespace to new_root and moves the old root (outside namespace) to the directory put_old. So that when you will look the process root directory outside the namespace, it will symlink to / instead of the any deeper hierarchy in the filesystem, similar to how chroot works.
Don't worry if you aren't getting it right now. This is a theory part, I will recap the chroot breakout and I am sure then you will understand it better.
The chroot Problem with Containers
In the recent post "Docker Resource Management in Detail", I have used the chroot program to quickly show you how the containers can be created without using runc or containerd services. But is that enough? What about the security and chroot breakout?
Create a file secret file outside the namespace and save as /bin/secret. You can write any string into it, but I have used $RANDOM$RANDOM, to save the thinking overhead.

Switch over to the chroot'ed environment and try to list the files in the /bin directory. It won't show any file named secret in that directory. This totally makes sense, because for the current process and it's children the root directory is changed, /bin/ in the chroot is no longer points to the same /bin/ outside the namepace.
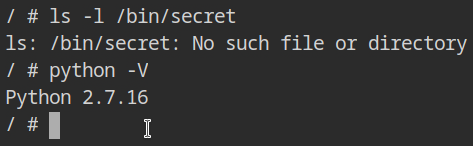
Python is already installed inside the namepace, and the process appears to be running as root user, copy and paste the chroot escape exploit from one of my older post (check out resources section).
import os
if not os.path.exists("chroot"):
os.mkdir("chroot")
os.chroot("chroot")
for _ in range(1000):
os.chdir("..")
os.chroot(".")
os.system("/bin/bash")Running this exploit will start the bash shell in the root directory outside the namespace and break free the chroot'ed jail. The output will resemble the screenshot below.
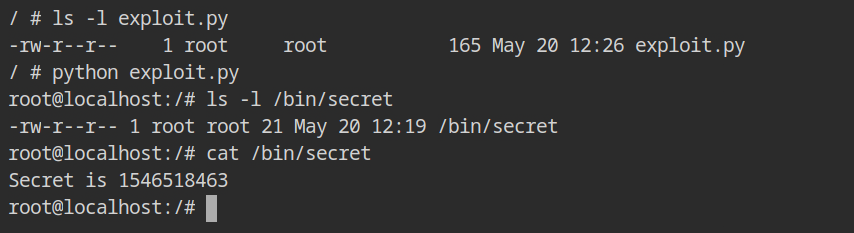
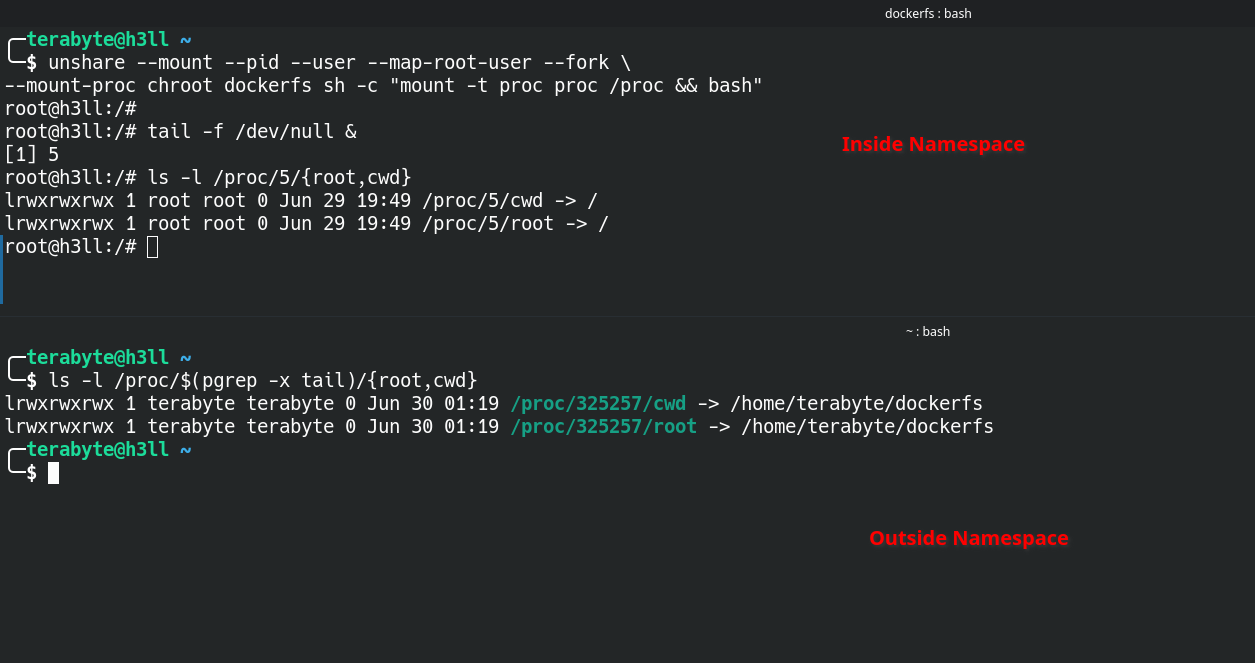
This second chroot is possible because the user is running with the effective UID of the root user, because of the -r/--map-root-user flag passed to the unshare command. It is required to setup initial mount for the procfs in /proc directory.
I am too lazy to set up everything on the AttackDefense lab again, therefore used the following command to set up the vulnerable namespace, without control groups.
unshare --mount --pid --user --map-root-user --fork \
--mount-proc chroot dockerfs sh -c "mount -t proc proc /proc && bash"The child process inside this namespace, which is the very first sh process, will naturally inherit its current working directory and root directory from the parent process. But when you will look the same process outside the namespace, both root and current working directory are mapped to /home/terabyte/dockerfs, not /.
Fixing the vulnerability with Pivot Root
It is necessary for performing a successful pivot root to start a new bash process in the namespace without chrooting, configure the procfs, and bind mount the dockerfs to itself. This is because it used to swap the root inside the mount namespace.
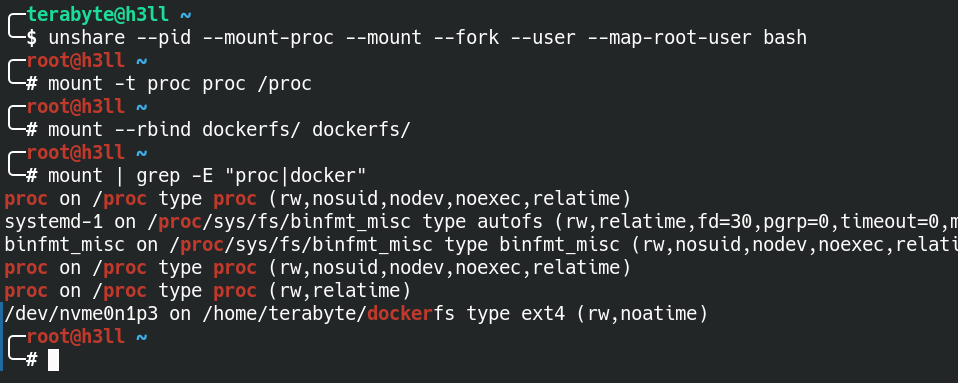
dockerfs to itselfIt is also required to have both new_root and put_old as directories in the file system, where the directory referencing the put_old must be child of the new_root. You can create a directory in the dockerfs and then pivot root into it as shown below. This will now promote the current directory as the root / in the mount table inside the namespace.
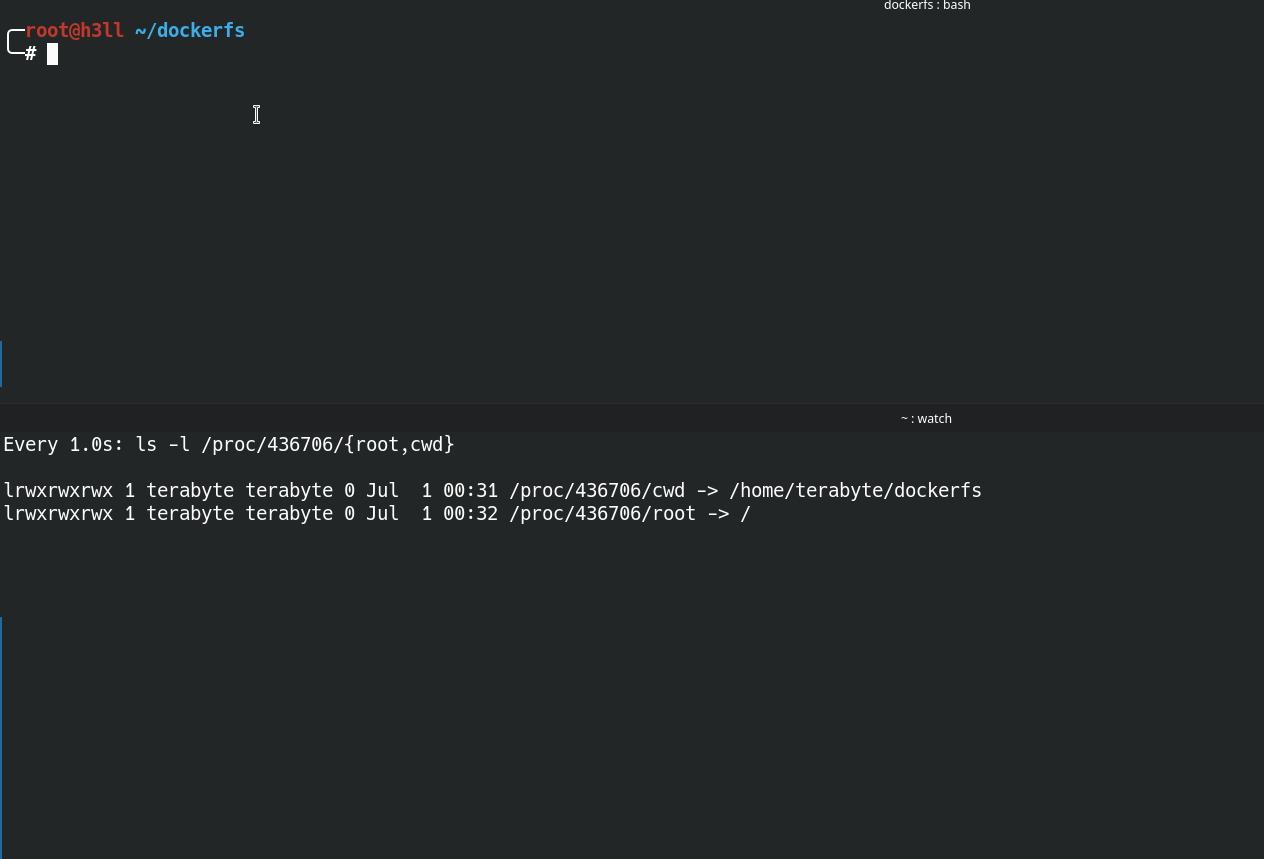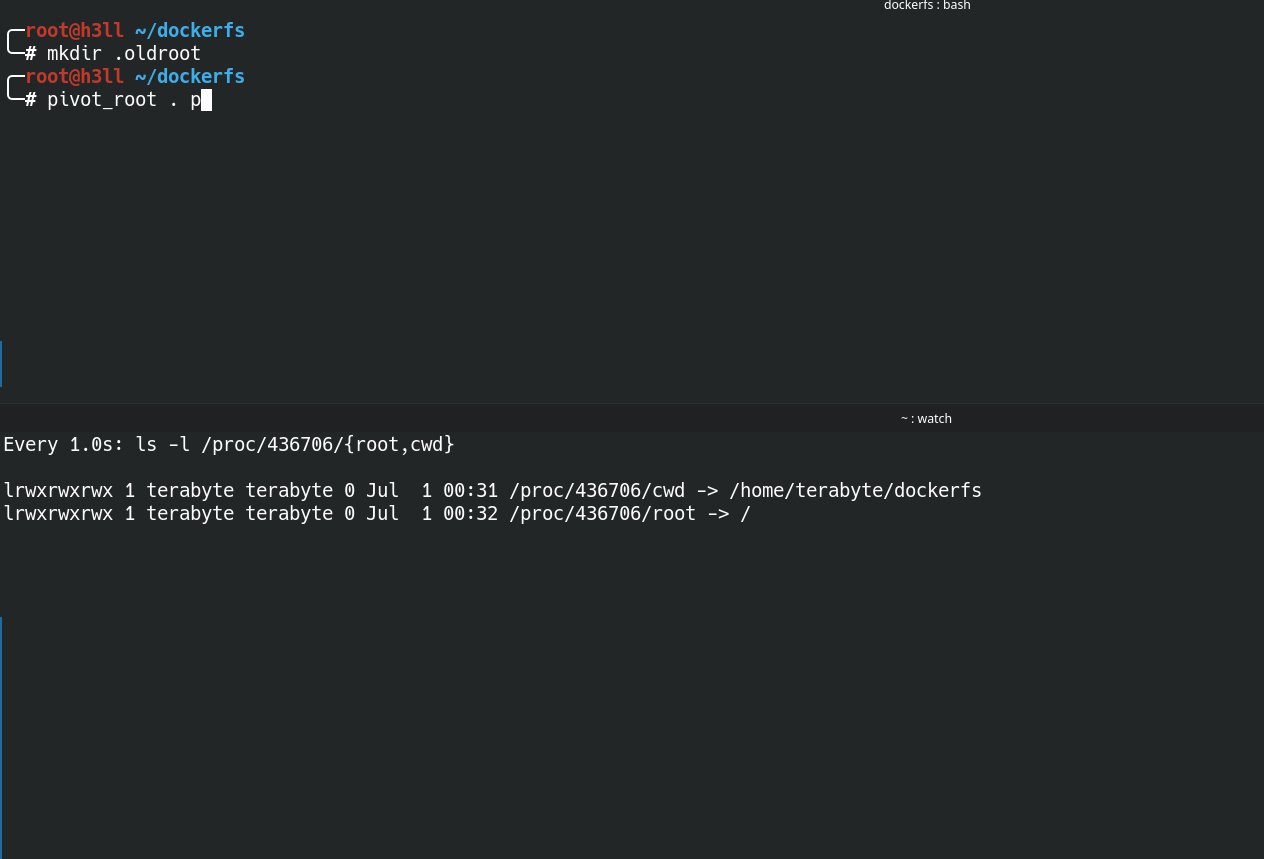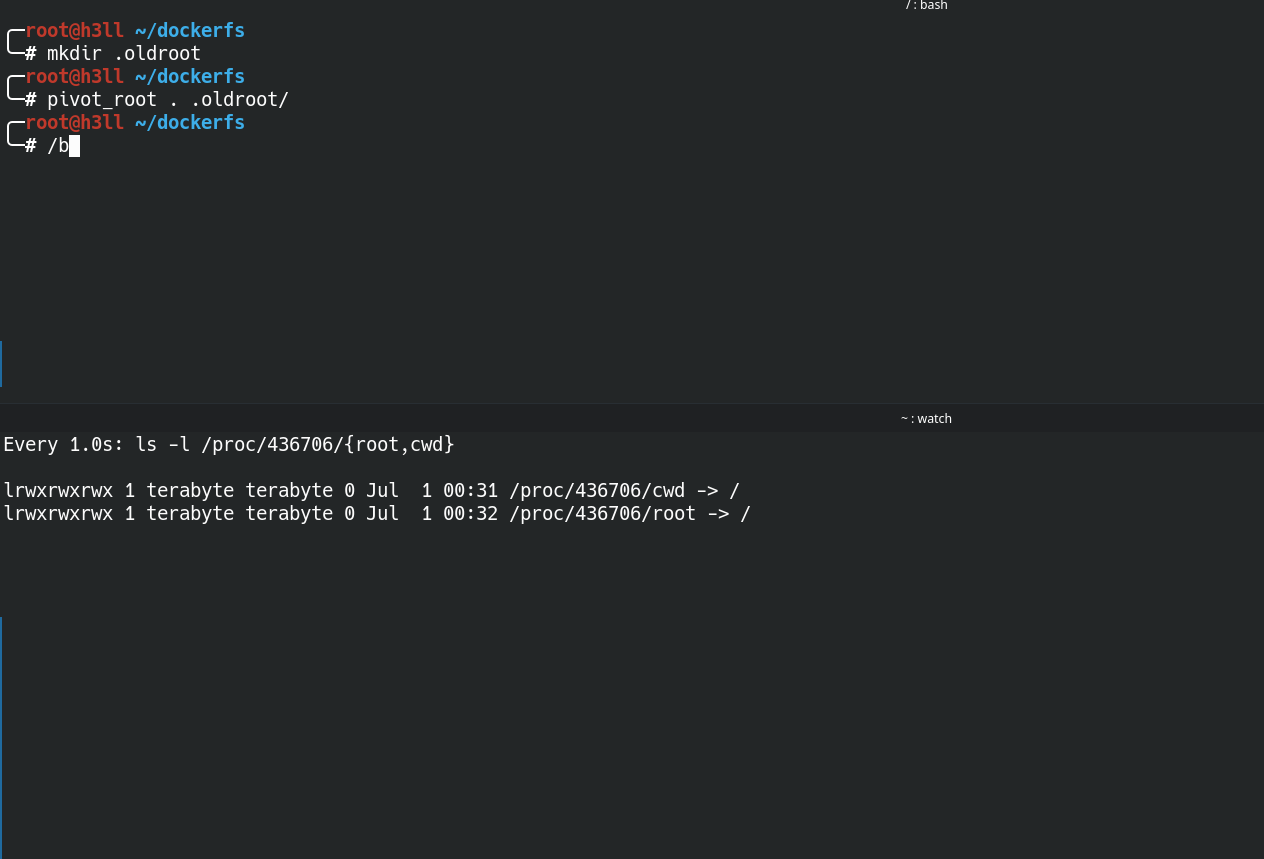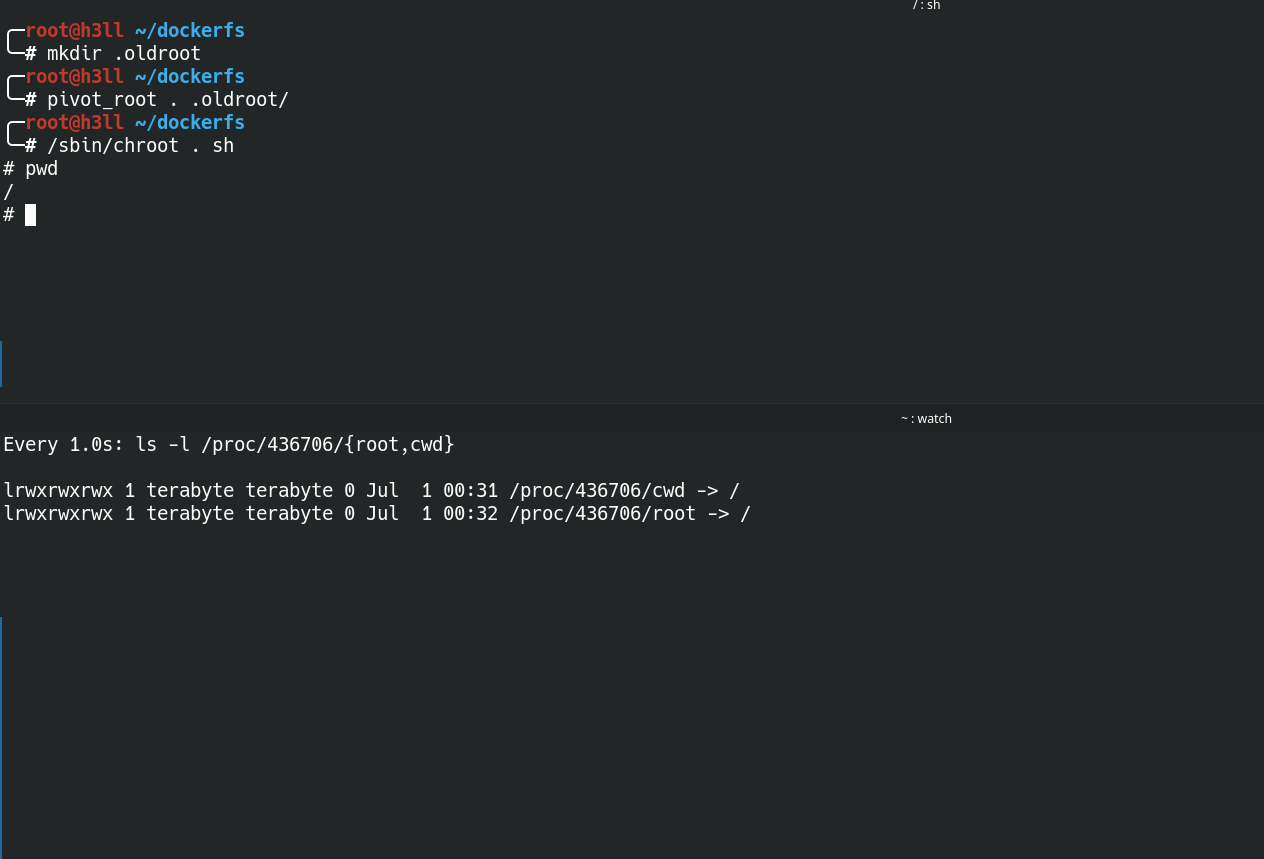
If you would look into the .oldroot directory, it will now contain the old root file system and this information will also be reflected to the mount table inside the namespace, and you will see that the root directory is replaced with /.oldroot directory. Isn't it wierd?
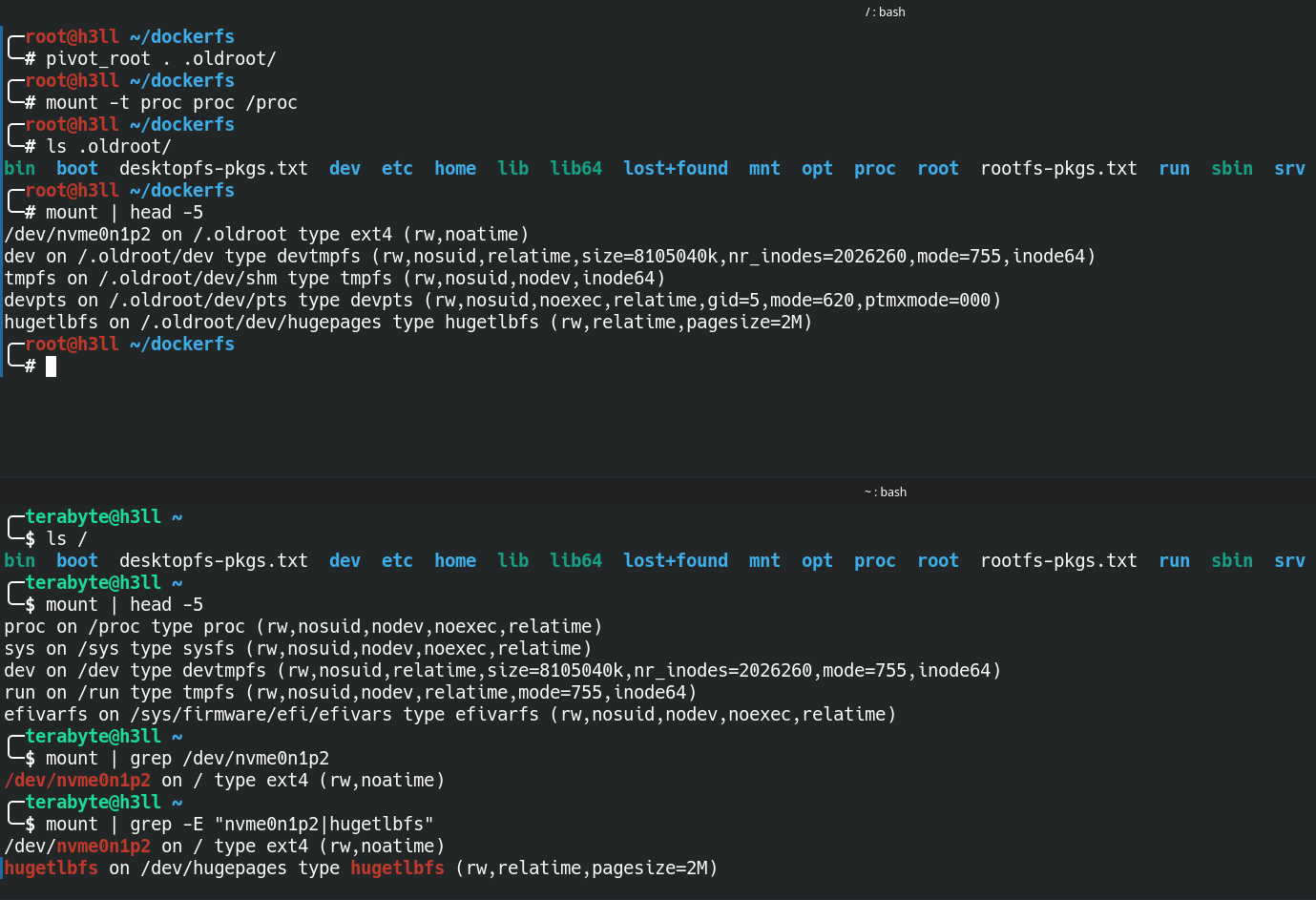
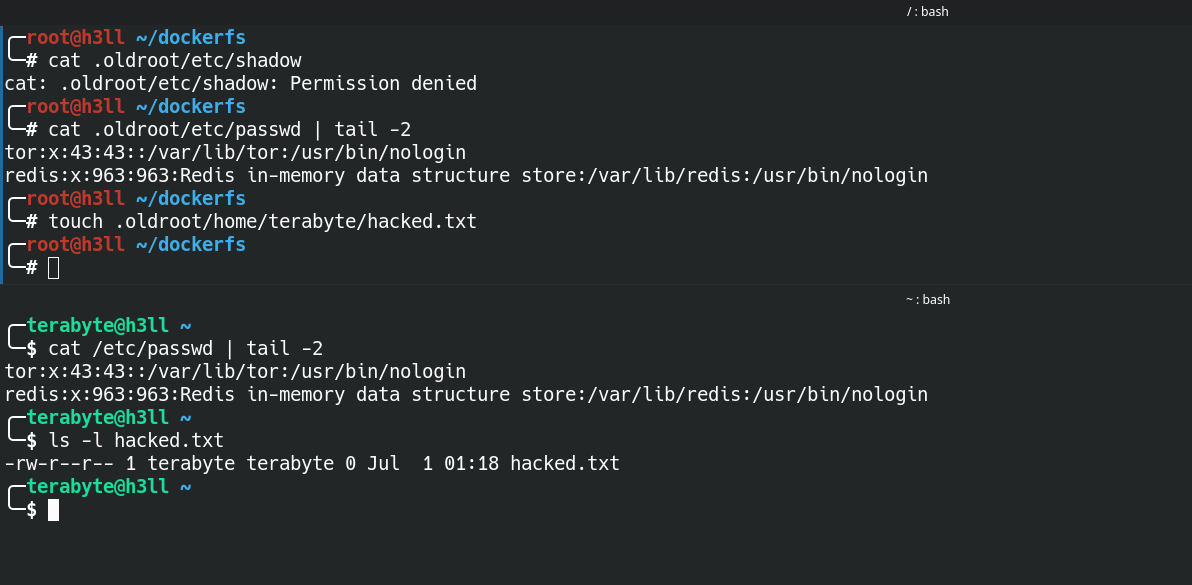
.oldroot directory.The process in outside this namespace is running as the low privileged user (terabyte), therefore any high privileged activities will be denied, but it can still perform read-write into the home directory of the user (/home/terabyte). This is still not true isolation that we are looking for 🙁.
Since the new rootfs is now ready, it seems safe to unmount the .oldroot which will make the folder empty. To make it work, make sure you remount the procfs into /proc directory which will be used to get the mount table inside namespace. After this, it is safe to chroot into the current filesystem and this time the old chroot breakout exploit will not work.
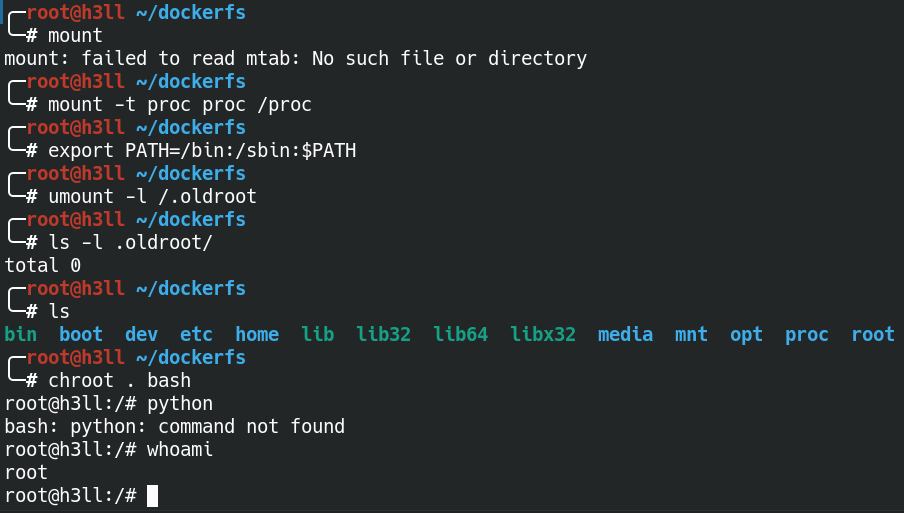
If you would list the entries from the mount table, it will show only the following two. There is no way (at least known to me) to get back to the old mountpoints.
/dev/nvme0n1p3 on / type ext4 (rw,noatime)
proc on /proc type proc (rw,relatime)References
- https://tbhaxor.com/breaking-out-of-chroot-jail-shell-environment/#what-is-chroot-anyway
- https://github.com/opencontainers/runtime-spec/blob/39c287c415bf86fb5b7506528d471db5405f8ca8/config.md#prestart
- https://itnext.io/linux-container-from-scratch-339c3ba0411d
- https://news.ycombinator.com/item?id=23167383
- https://www.infoq.com/articles/build-a-container-golang/
- https://thomasvanlaere.com/posts/2020/04/exploring-containers-part-1
- https://www.redhat.com/sysadmin/mount-namespaces